Real3D-Portrait
Introduction
介绍了一种音视频驱动下合成讲话视频的框架
| 之前的研究 | 缺点 |
|---|---|
| 直接通过图片用GAN生成照片级的视频 | 没有3D模型的参与,头部在剧烈运动时会产生大量artifacts |
| 基于NeRF的3D方法,有了3D模型和纹理细节 | 无法通用,针对某人训练后,才能生成这个人的视频 |
| 3D模型有了一些进展后,可以通过EG3D学习一个hidden space去生成某一个身份的视频 | 无法同时实现准确的重建和动画 |
| 先生成2D视频,然后通过3D GAN inversion生成3D模型 | 但是动画方面会有artifacts(Temporal jitters和图像失真) |
| 先从图像中预测3D模型,然后根据音视频对模型变形 | 由于输入图片角度少,姿势变化小,因此生成模型的鲁棒性比较差 |
因此设定了下目标
- 重建模型
- 从一个现有的人脸生成模型中蒸馏出3D先验知识,来预训练一个I2P(Image to plane)模型,I2P的作用是将输入图像转变成3D模型
- 实现动画
- 设计了MA(Motion Adapter)来将PNCC(Projected Normalized Coordinate Code)序列转化成3D下的模型变形参数
- 提高躯干和背景之间的自然度
- 现有的方法要么对头部和躯干建模,要么就只对头部建模,都忽略了背景的重要性。
- 因此该方法分别对头部、躯干、背景进行建模,最后再进行合成操作
- 设计了HTB-SR(Head-Torso-Background)模型
- 超分辨率分支(体渲染的太糊)
- 躯干分支(基于2D像素而非3D模型变换的)
- 背景分支(实现背景切换)
为了实现音频驱动,设计了一个A2M(Audio to Motion)将音频信号转化为PNCC序列,通用性很强,而且可以手动控制眨眼和嘴唇幅度
Pipeline
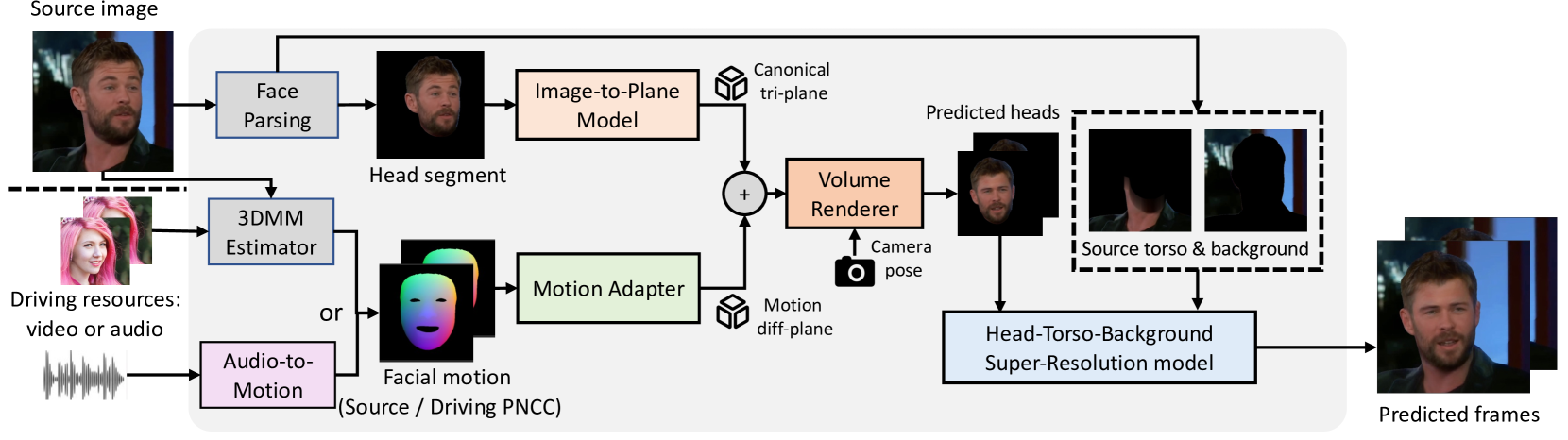
主要是四个模型:I2P、MA、HTB-SR、A2M
Related Work
工作聚焦在两点:重建+动画
- 如何从输入图片中准确重建3D人脸
- 如何使模型变形及渲染情况能够和输入的视/音频一致
重建
- 早期是3DMM(3D Morphable Model)方法
- 重建的面部网格具有低保真度并且没有细节 例如皱纹
- 只有面部才被模型参数化,并且无法表示其他的地方(头发、帽子、眼镜)
- 之后是基于NeRF的3D头部表示
- 早期的基于NeRF的3D重建一般都是根据特定身份形象进行训练,一个形象的训练就得10h+
- 最近的Tri-plane表示方法是最新的快速且高质量的基于NeRF的3D人脸重建的基础
- 还有一些通过预测器直接将图片映射到Tri-plane,不经过3D,在推理中更高效稳定
这篇论文的I2P就基于预测器
动画
- 早期的2D面部动画直接采用GAN生成
- 训练不稳定
- 视觉质量差
- 后来是warping-based方法
- 实现了高度的身份匹配
- 没有严格的3D约束,头部运动剧烈时会产生artifacts和扭曲
- 之前的都是基于2D的建模,多少都会引起artifacts,因此出现了很多基于3D的方法
- 最早的基于3DMM
- 对输入图像进行3D重建,然后将3DMM合并到人脸渲染过程中
- 由于3DMM的缺陷,会造成信息丢失,无法生成照片级的效果
- 基于NeRF的人脸生成
- 高保真度,严格几何约束
- 但是需要对特定人训练且时间过长
- Tri-plane表示的基于NeRF的one-shot
- 第一类
- 2D动画+3D提升
- 图片经过模型生成2D讲话视频,然后通过3D GAN inversion提升到3D
- inversion不稳定
- 头部大幅移动时表现较差
- 2D动画+3D提升
- 第二类
- 3D重建+3D动画
- 通过学习来预测3D模型,然后再变形3D模型
- 数据集通常缺乏大幅移动的帧,3D重建的泛化能力不理想
- 3D重建+3D动画
- 第一类
- 最早的基于3DMM
Real3D-Portiart
流程细节

I2P重建头部模型
模型设计
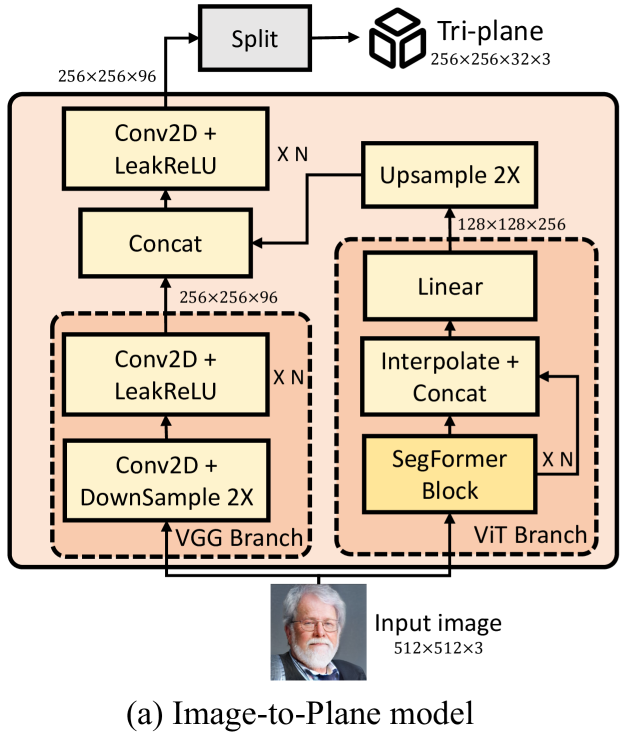
- ViT Branch
- VGG Branch
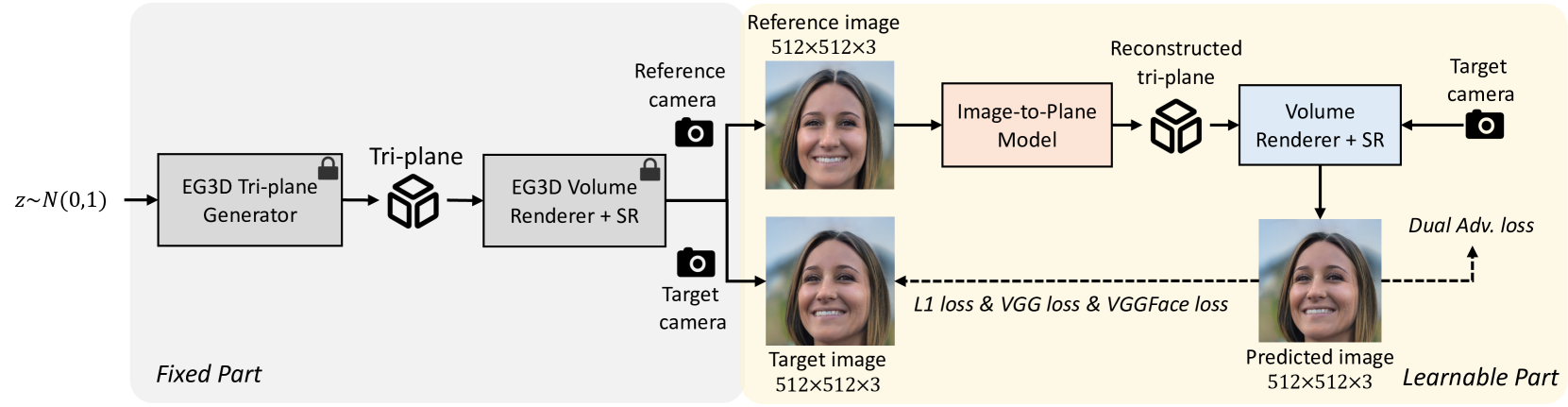
模型训练
MA进行运动预测
模型设计
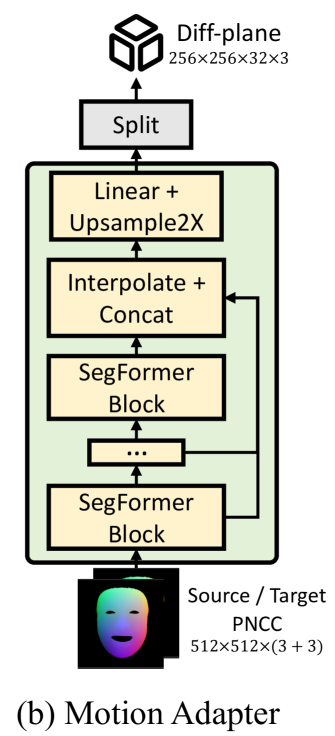
- PNCC
- 参数i,e
- $NCC_d = \frac{\bar S_d - min(\bar S_d)}{max(\bar S_d)-min(\bar S_d)},\space (d=x,y,z)$
- $PNCC_{drv}=Z_BUFFER(3DMM_Mesh(i_{src},e_{drv}),NCC)$
模型训练

- 图像生成函数
- $I_{drv}=SR(VR(P_{cano}+P_{diff},cam)),\space s.t.,\space P_{cano}=I2P(I_{src}),\space P_{diff}=MA(PNCC_{drv},PNCC_{src})$
- 损失计算
- $\mathcal{L} = ||I_{tgt}-I^,{tgt}||^1_1+\mathcal{L}{VGGs}(I_{tgt},I^,{tgt})+\mathcal{L}{DualAdv}(I^,{tgt})+\mathcal{L}{Lap}$
- 给定三个帧的PNCC 期望中间帧的PNCC是前后两个帧PNCC的平均值
- $\mathcal{L}{Lap}=||MA(PNCC_t)-0.5\times(MA(PNCC{t-1})+MA(PNCC_{t+1}))||^2_2$
- 四个损失相加
- L1损失
- 基于VGG19/VGGFace 感知损失
- 双重对抗性损失(保真度+一致性)
- 相邻帧拉普拉斯损失(时间抖动)
HTB-SR 建模躯干和背景以及合成
模型设计

- Torso Branch
- 基于像素预定义关键点
- $KP=IdxKP(R\cdot Vertex_{3D}+t)$
- $Vertex_{3D} \rightarrow 3DMM_Mesh(i_{src},e_{drv})$
- Background Branch
- KNN
- fuse
- Alpha-Blending Style
- $output = \alpha \cdot A + (1-\alpha) \cdot B$
- $F=(F_{head}\cdot M_{head}+F_{torso}\cdot (1-M_{head}))\cdot M_{person} + F_{bg}\cdot (1-M_{person})$
- F - feature map
- M - mask
- Alpha-Blending Style
模型训练
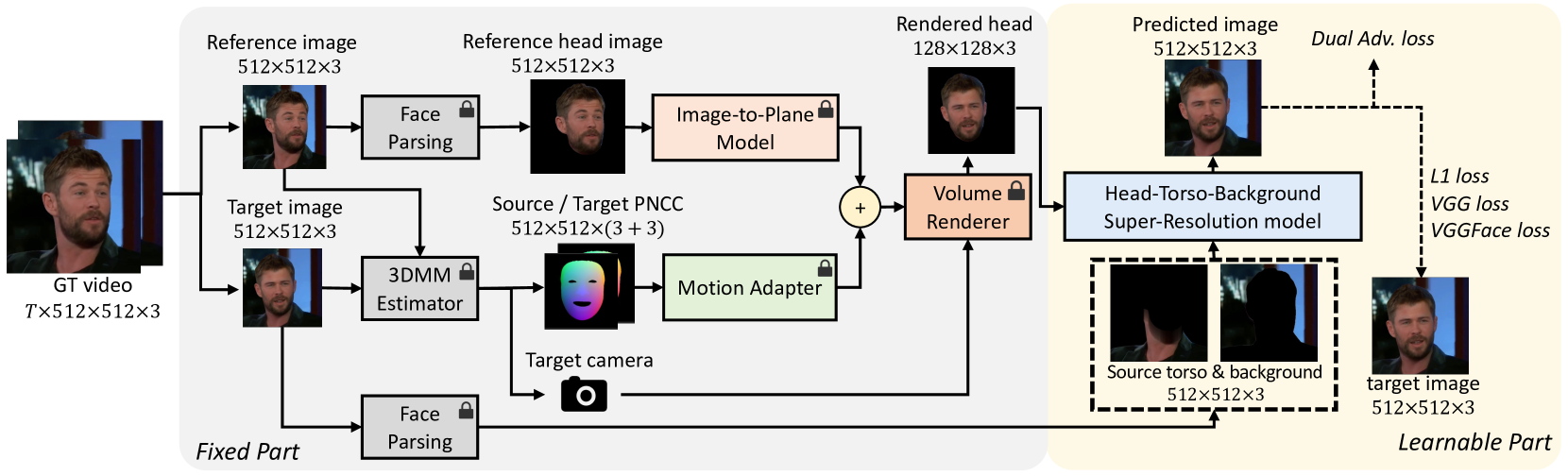
A2M 音频到$e_{drv}$
模型设计
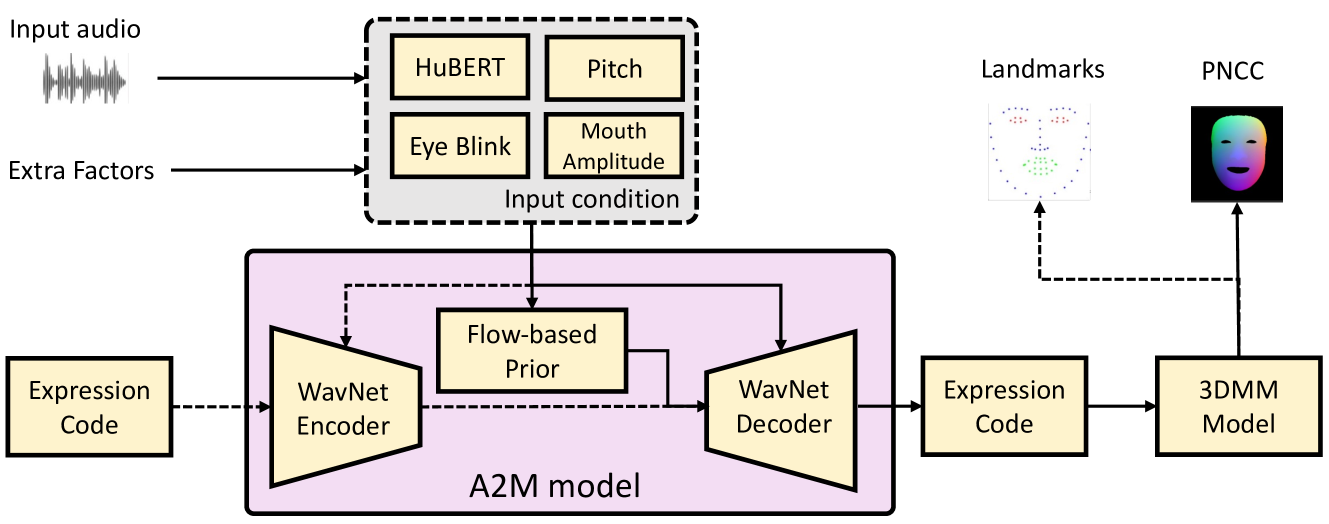
不是直接预测PNCC 而是预测3DMM参数
- 构建PNCC
- $PNCC_{drv}=Z_BUFFER(3DMM_Mesh(i_{src},e_{drv}),NCC)$
- $i_{src}$是身份系数 $e_{drv}$是从驱动视频中提取或者由A2M模型预测出的表达式系数
Experiment
主要指标
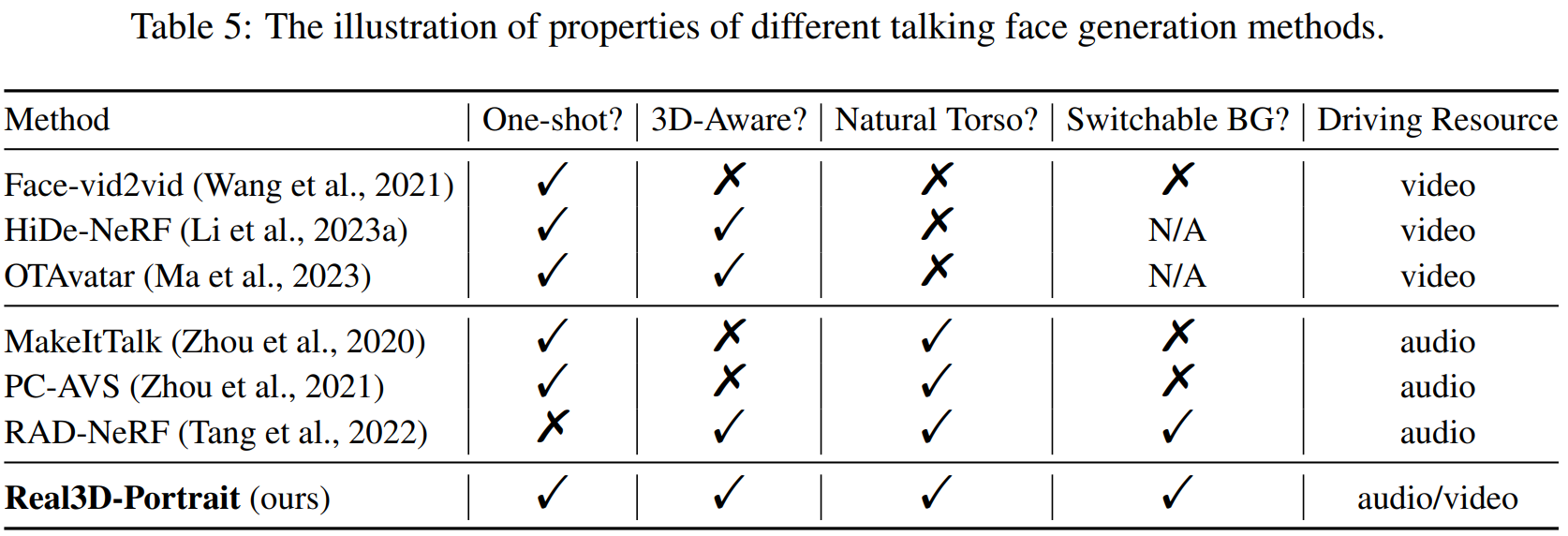
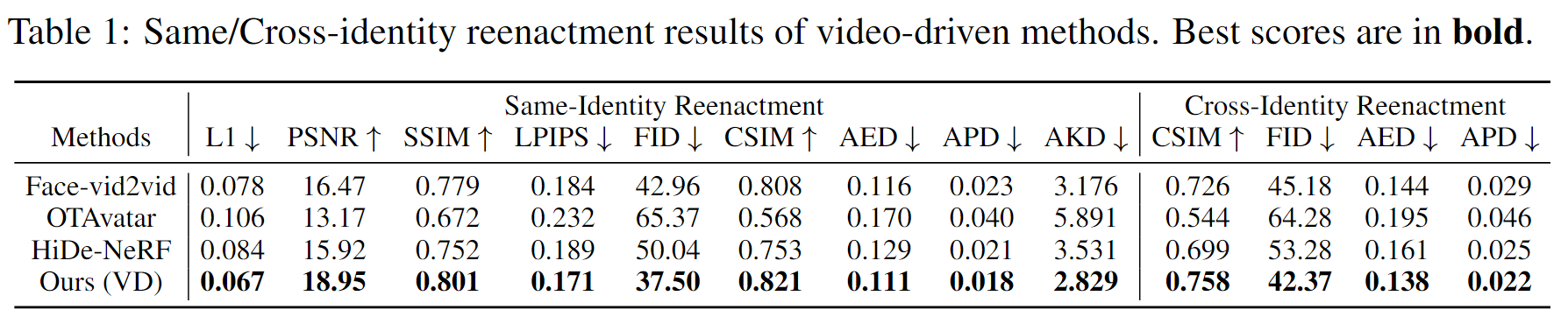
视频驱动方法比较
音频驱动方法比较

消融研究

I2P和MA
- 第一行
- 若没有预训练处理,身份相似度、图像质量、表达准确度都会大幅下降
- 第二行
- 微调在实现低AED方面同样很重要 我们猜测是因为预训练的I2P模型之学习了如何通过源表达式来重构avatar 他需要进一步更新去支持实现给定的目标表达式的面部动画
- 第三四行
- 87M参数量的效果明显好于40M参数量的效果,但87M与200M之间的效果差距不明显
- 第五行
- 拉普拉斯损失对于优化头部动画是很有必要的
HTB-SR
- 第1行
- 无监督关键点的视觉效果更差
- 第2行
- 发现Alpha-Blending风格的融合对于获得良好的身份保留和图像质量是很有必要的
- 第3行
- 发现移除背景修复处理,会导致图像质量更差
p.s.
PNCC表示的是某个特定人脸,存储的是该人脸的每个顶点数据与平均人脸每个顶点数据相比,每个点的偏移值
Tri-plane类似于三维坐标系,将三维场景中的信息压缩到三个二维平面上来,降低计算和存储成本,一般与体渲染结合
warping-based methods通过原始视频确定面部上的3D关键点,然后对应到2D图像上,直接对这些关键点进行拉伸扭曲变换